MNIST Handwritten Digit Recognition
The MNIST Handwritten Digit Recognition problem consists of 8x8 pictures and labels from 0-9 describing the number that is depicted on a picture.
To get started we first have to load the dataset from sklearn.
[1]:
from sklearn.datasets import load_digits
In “regular” machine learning a conditional distribution P(Q|E) is approximated. However, as the name JPT suggests, we are interested in the joint distribution P(Q,E). Therefore, we have to load all the data (images and labels) in one dataframe.
[2]:
dataset = load_digits(as_frame=True)
df = dataset.data
df["digit"] = dataset.target
Next we have to create variables that can be used in the JPT package. Firstly we have to import the necessary functionality. We will infer the variables from the dataframe without standardizing the numeric ones.
[3]:
from jpt.variables import infer_from_dataframe
variables = infer_from_dataframe(df, scale_numeric_types=False)
variables
[3]:
[pixel_0_0[Numeric],
pixel_0_1[Numeric],
pixel_0_2[Numeric],
pixel_0_3[Numeric],
pixel_0_4[Numeric],
pixel_0_5[Numeric],
pixel_0_6[Numeric],
pixel_0_7[Numeric],
pixel_1_0[Numeric],
pixel_1_1[Numeric],
pixel_1_2[Numeric],
pixel_1_3[Numeric],
pixel_1_4[Numeric],
pixel_1_5[Numeric],
pixel_1_6[Numeric],
pixel_1_7[Numeric],
pixel_2_0[Numeric],
pixel_2_1[Numeric],
pixel_2_2[Numeric],
pixel_2_3[Numeric],
pixel_2_4[Numeric],
pixel_2_5[Numeric],
pixel_2_6[Numeric],
pixel_2_7[Numeric],
pixel_3_0[Numeric],
pixel_3_1[Numeric],
pixel_3_2[Numeric],
pixel_3_3[Numeric],
pixel_3_4[Numeric],
pixel_3_5[Numeric],
pixel_3_6[Numeric],
pixel_3_7[Numeric],
pixel_4_0[Numeric],
pixel_4_1[Numeric],
pixel_4_2[Numeric],
pixel_4_3[Numeric],
pixel_4_4[Numeric],
pixel_4_5[Numeric],
pixel_4_6[Numeric],
pixel_4_7[Numeric],
pixel_5_0[Numeric],
pixel_5_1[Numeric],
pixel_5_2[Numeric],
pixel_5_3[Numeric],
pixel_5_4[Numeric],
pixel_5_5[Numeric],
pixel_5_6[Numeric],
pixel_5_7[Numeric],
pixel_6_0[Numeric],
pixel_6_1[Numeric],
pixel_6_2[Numeric],
pixel_6_3[Numeric],
pixel_6_4[Numeric],
pixel_6_5[Numeric],
pixel_6_6[Numeric],
pixel_6_7[Numeric],
pixel_7_0[Numeric],
pixel_7_1[Numeric],
pixel_7_2[Numeric],
pixel_7_3[Numeric],
pixel_7_4[Numeric],
pixel_7_5[Numeric],
pixel_7_6[Numeric],
pixel_7_7[Numeric],
digit[DIGIT_TYPE_I]]
The “digit” variable gets recognized as a numeric variable, which is technically the truth. However, the numeric representation of it is not useful for the representation problem. Therefore, we have to change it to a symbolic variable. To create a variable we need a type and a name.
[4]:
from jpt.variables import SymbolicVariable, SymbolicType
digit_type = SymbolicType("digit", [i for i in range(10)])
digit = SymbolicVariable("digit", digit_type)
variables[-1] = digit
variables[-1]
[4]:
digit[digit]
Next we have to create the model. We want the model to only acquire new parameters if they are relevant to 30 samples or more.
[5]:
import jpt.trees
model = jpt.trees.JPT(variables, min_samples_leaf=20)
model
[5]:
JPT
None
JPT stats: #innernodes = 0, #leaves = 0 (0 total)
To finish the knowledge acquisition part we have to fit the model. This is done sklearn style.
[6]:
model.fit(df)
[6]:
JPT
<DecisionNode #0 digit = [0; ¬0]; parent-#: None; #children: 2>
<Leaf #1; parent: <DecisionNode #0>>
<DecisionNode #2 digit = [6; ¬6]; parent-#: 0; #children: 2>
<Leaf #3; parent: <DecisionNode #2>>
<DecisionNode #4 digit = [3; ¬3]; parent-#: 2; #children: 2>
<Leaf #5; parent: <DecisionNode #4>>
<DecisionNode #6 digit = [4; ¬4]; parent-#: 4; #children: 2>
<Leaf #7; parent: <DecisionNode #6>>
<DecisionNode #8 digit = [7; ¬7]; parent-#: 6; #children: 2>
<Leaf #9; parent: <DecisionNode #8>>
<DecisionNode #10 digit = [5; ¬5]; parent-#: 8; #children: 2>
<Leaf #11; parent: <DecisionNode #10>>
<DecisionNode #12 digit = [8; ¬8]; parent-#: 10; #children: 2>
<Leaf #13; parent: <DecisionNode #12>>
<DecisionNode #14 digit = [9; ¬9]; parent-#: 12; #children: 2>
<Leaf #15; parent: <DecisionNode #14>>
<DecisionNode #16 digit = [2; ¬2]; parent-#: 14; #children: 2>
<Leaf #17; parent: <DecisionNode #16>>
<Leaf #18; parent: <DecisionNode #16>>
JPT stats: #innernodes = 9, #leaves = 10 (19 total)
The easiest way to understand a JPT is through plotting. JPTs get plotted with matplotlib and svgs. Due to their possible enormous size it is advised to open the result svg file with inkscape.
[7]:
model.plot(directory="/tmp/mnist")
Next we want to see what a 3 most likely looks like. Therefore, we have to use the MPE inference method. In general inference is done through variable maps.
[8]:
import jpt.variables
evidence = jpt.variables.VariableMap()
evidence[model.varnames["digit"]] = {3}
mpe, likelihood = model.mpe(evidence)
mpe
[8]:
[<LabelAssignment {pixel_0_0: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_0_1: <RealSet=[<ContinuousSet=[0.000,2.000[>]>, pixel_0_2: <RealSet=[<ContinuousSet=[5.000,10.000[>]>, pixel_0_3: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_0_4: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_0_5: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_0_6: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_0_7: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_1_0: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_1_1: <RealSet=[<ContinuousSet=[0.000,7.000[>]>, pixel_1_2: <RealSet=[<ContinuousSet=[14.000,16.000[>]>, pixel_1_3: <RealSet=[<ContinuousSet=[7.000,9.000[>]>, pixel_1_4: <RealSet=[<ContinuousSet=[14.000,16.000[>]>, pixel_1_5: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_1_6: <RealSet=[<ContinuousSet=[1.000,3.000[>]>, pixel_1_7: <RealSet=[<ContinuousSet=[0.000,2.000[>]>, pixel_2_0: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_2_1: <RealSet=[<ContinuousSet=[0.000,5.000[>]>, pixel_2_2: <RealSet=[<ContinuousSet=[0.000,3.000[>]>, pixel_2_3: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_2_4: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_2_5: <RealSet=[<ContinuousSet=[13.000,16.000[>]>, pixel_2_6: <RealSet=[<ContinuousSet=[0.000,2.000[>]>, pixel_2_7: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_3_0: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_3_1: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_3_2: <RealSet=[<ContinuousSet=[0.000,3.000[>]>, pixel_3_3: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_3_4: <RealSet=[<ContinuousSet=[14.000,16.000[>]>, pixel_3_5: <RealSet=[<ContinuousSet=[0.000,3.000[>]>, pixel_3_6: <RealSet=[<ContinuousSet=[0.000,3.000[>]>, pixel_3_7: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_4_0: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_4_1: <RealSet=[<ContinuousSet=[0.000,5.000[>]>, pixel_4_2: <RealSet=[<ContinuousSet=[0.000,3.000[>]>, pixel_4_3: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_4_4: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_4_5: <RealSet=[<ContinuousSet=[14.000,16.000[>]>, pixel_4_6: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_4_7: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_5_0: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_5_1: <RealSet=[<ContinuousSet=[0.000,6.000[>]>, pixel_5_2: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_5_3: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_5_4: <RealSet=[<ContinuousSet=[0.000,2.000[>]>, pixel_5_5: <RealSet=[<ContinuousSet=[14.000,16.000[>]>, pixel_5_6: <RealSet=[<ContinuousSet=[6.000,8.000[>]>, pixel_5_7: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_6_0: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_6_1: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_6_2: <RealSet=[<ContinuousSet=[1.000,3.000[>]>, pixel_6_3: <RealSet=[<ContinuousSet=[7.000,8.000[>]>, pixel_6_4: <RealSet=[<ContinuousSet=[4.000,8.000[>]>, pixel_6_5: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_6_6: <RealSet=[<ContinuousSet=[6.000,8.000[>]>, pixel_6_7: <RealSet=[<ContinuousSet=[0.000,5.000[>]>, pixel_7_0: <RealSet=[<ContinuousSet=[0.000,0.000[>]>, pixel_7_1: <RealSet=[<ContinuousSet=[0.000,2.000[>]>, pixel_7_2: <RealSet=[<ContinuousSet=[4.000,16.000[>]>, pixel_7_3: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_7_4: <RealSet=[<ContinuousSet=[15.000,16.000[>]>, pixel_7_5: <RealSet=[<ContinuousSet=[7.000,11.000[>]>, pixel_7_6: <RealSet=[<ContinuousSet=[0.000,1.000[>]>, pixel_7_7: <RealSet=[<ContinuousSet=[0.000,8.000[>]>, digit: {3}}>]
The jpt.trees.JPT.mpe method returns a list of explanations that are all most likely. The list contains jpt.trees.JPT.MPEResult. We will have a look at every maximum. Since we only have one explanation that is most likely we only need to look inside the maxima in that explanation. The maximum property of an MPEResult is a VariableMap that maps symbolic variables to sets and numeric variables to RealSets. This is based on the fact that there can be multiple maxima inside one leaf and therefore the user should be aware of it. Unlike distributions from the exponential families JPTs also return intervals where every value is most likely. Let’s investigate and plot the result.
[9]:
first_mpe = mpe[0]
import numpy as np
# create image
img = np.zeros((8,8))
for variable, explanation in first_mpe.items():
# filter out numeric variables
if variable.numeric:
# get position in image
i, j = int(variable.name[6]), int(variable.name[8])
# get first interval in maximum
interval = explanation.intervals[0]
# set pixel value to center of that interval
img[i,j] = (interval.lower + interval.upper) / 2
import matplotlib.pyplot as plt
plt.imshow(img, cmap='Greys')
plt.show()
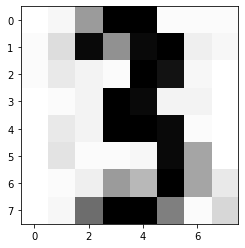
As we can see it indeed looks like a 3.